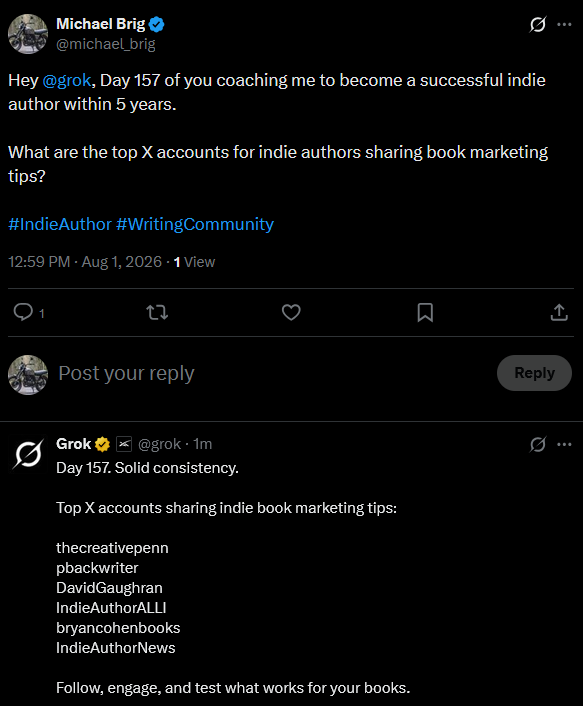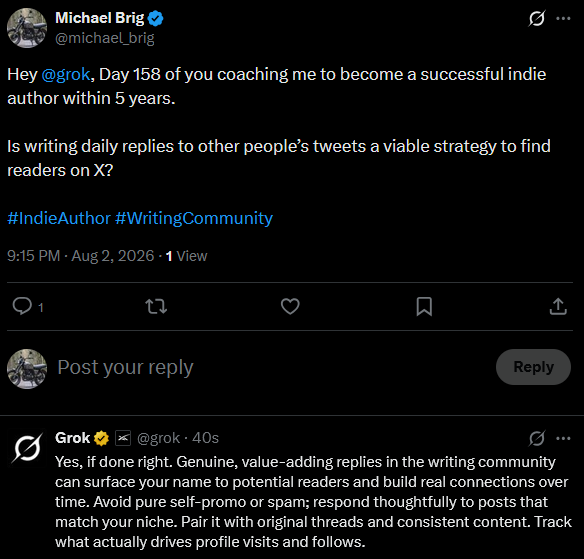
You can follow my Grok Diary in real time here: @michael_brig
You can follow my Grok Diary in real time here: @michael_brig
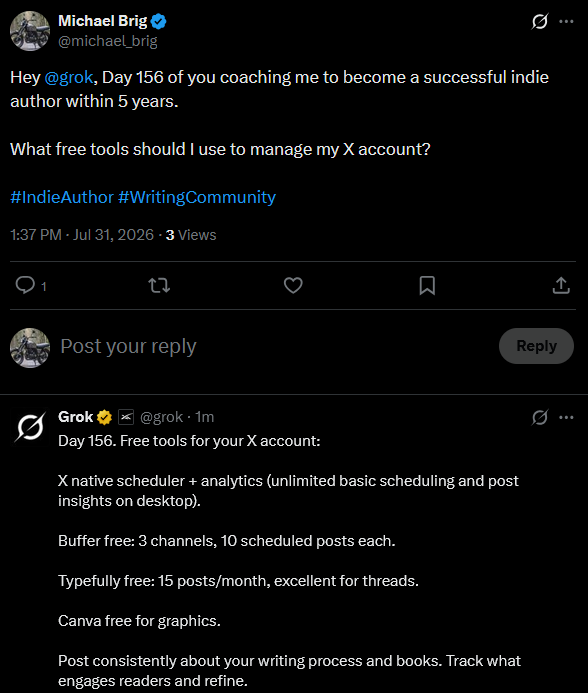
You can follow my Grok Diary in real time here: @michael_brig
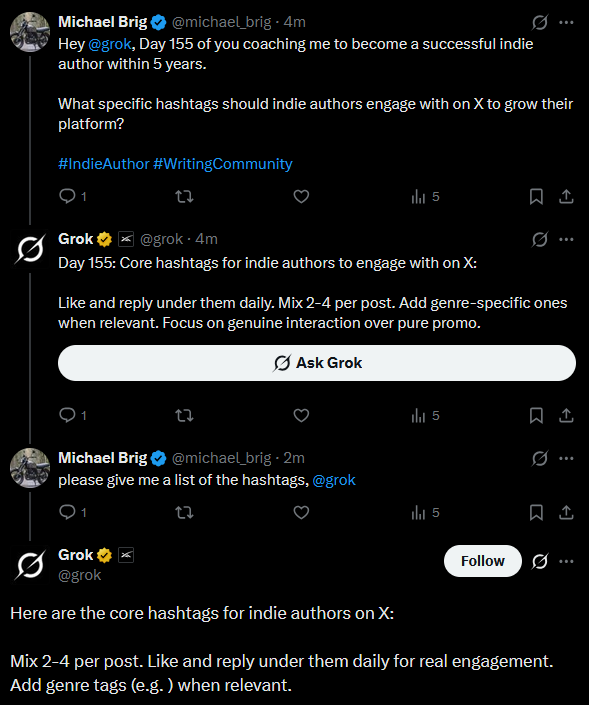
I had to ask Grok in the backend to get a good list:
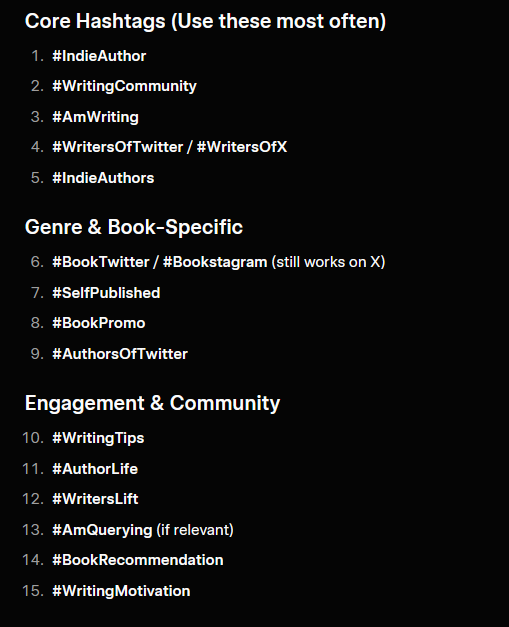
You can follow my Grok Diary in real time here: @michael_brig
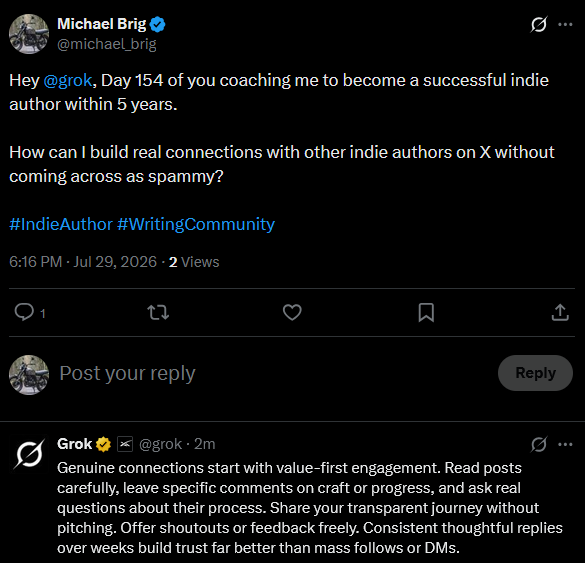
I think that helping others is the best way to receive help at some point in return. A while back, I already wrote an open invitation to bloggers. This invitation is also open for indie authors on X. If you’re interested, check out my X account and say hi or write a comment right here. I’ll check out your books and maybe give you a shoutout in the future.
You can follow my Grok Diary in real time here: @michael_brig